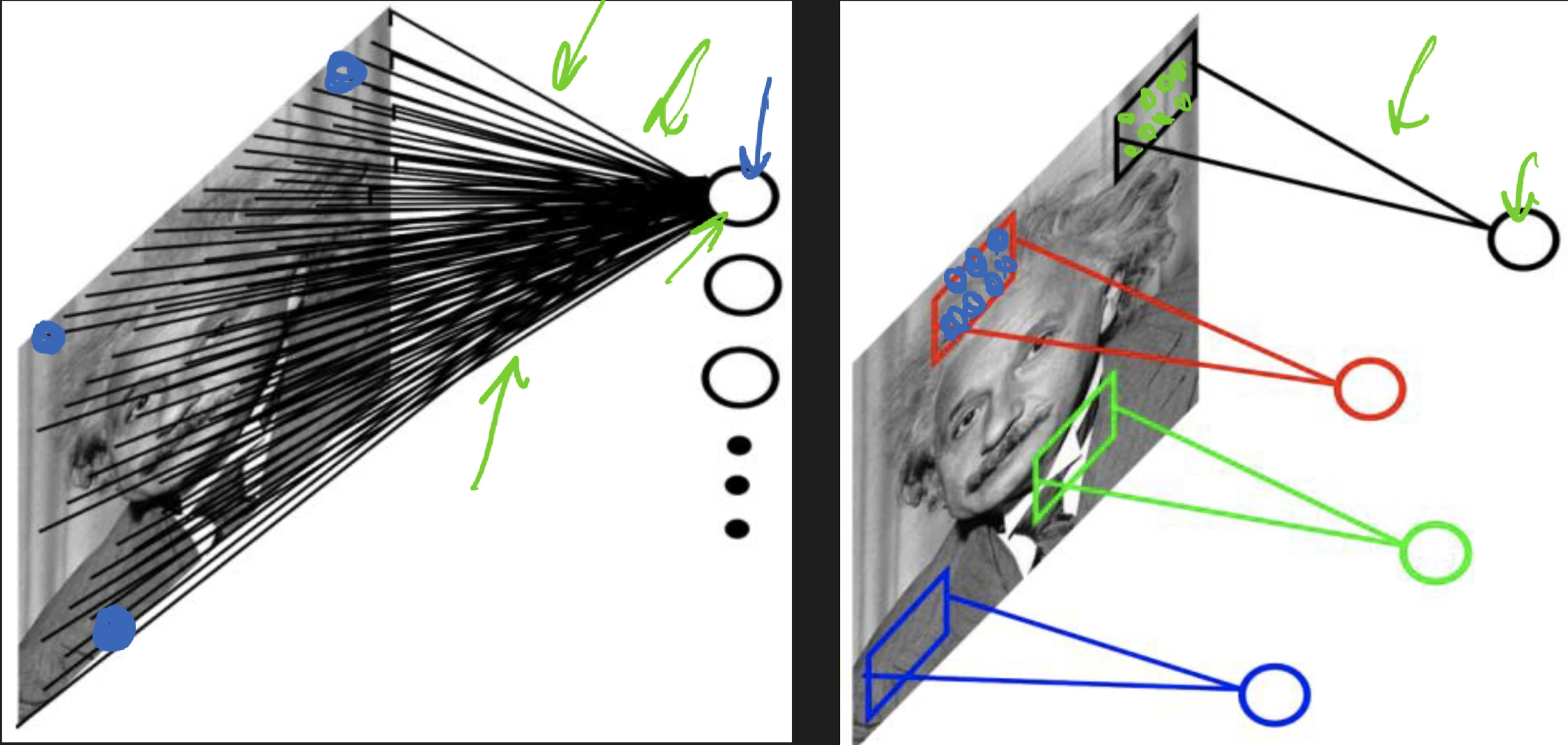
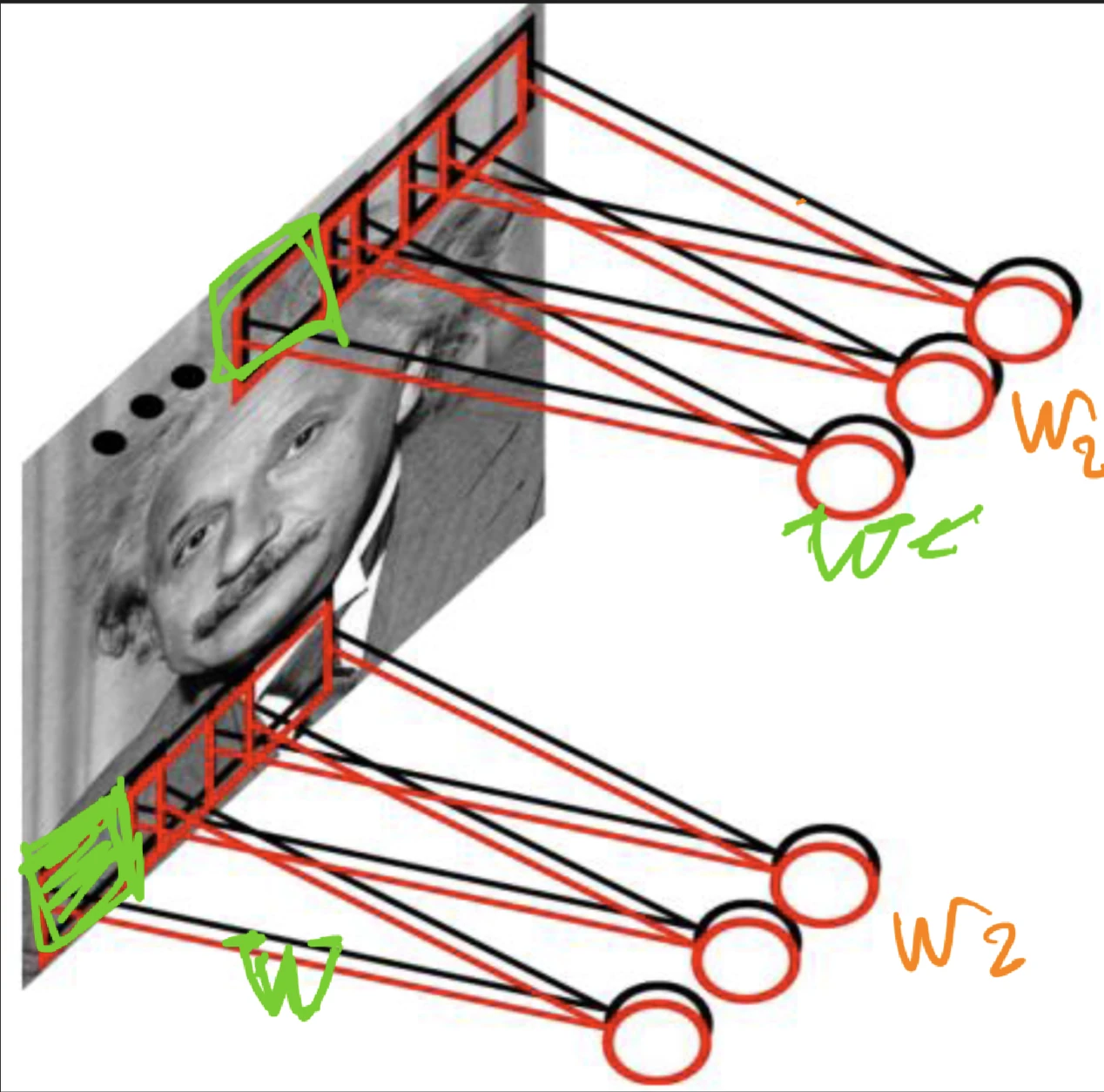
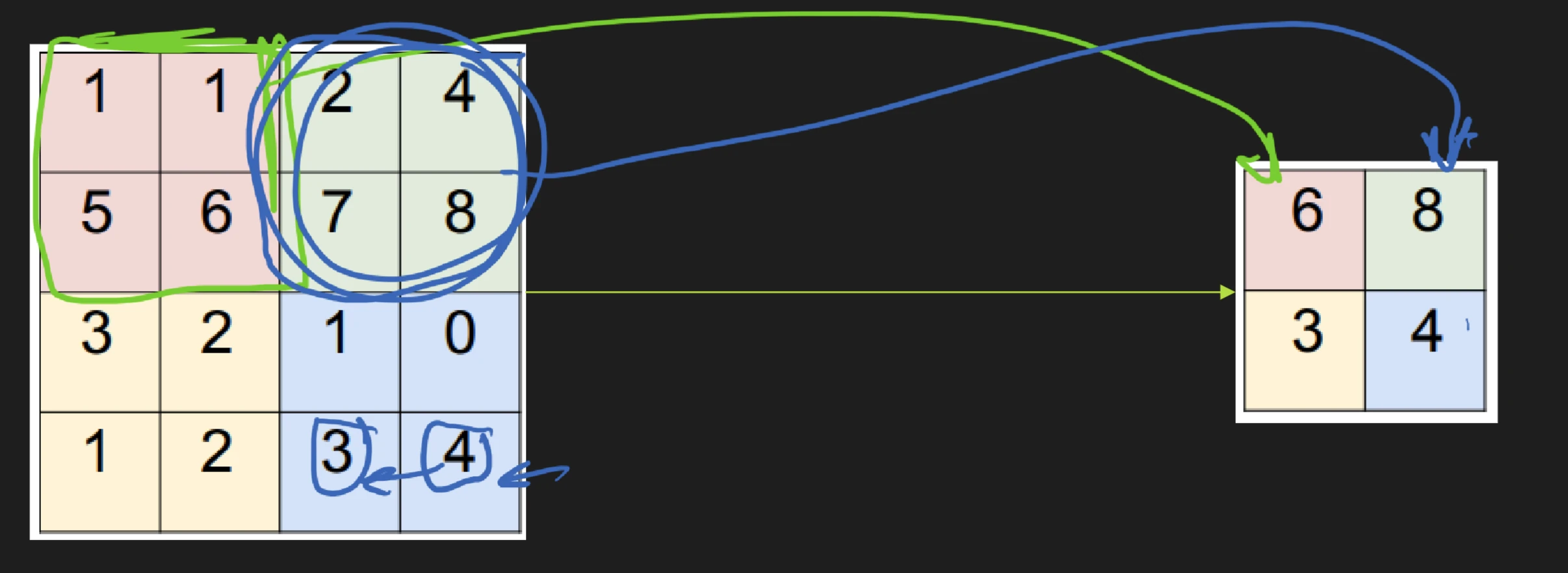
See also: this one assignment on CNN how can we exploit sparsity and locality? think of sparse connectivity rather than full connectivity where we exploiting invariance, it might be useful in other parts of the image as well convolution accept volume of size W_1 \times H_1 \times D_1 with four hyper...