See also jupyter notebook
Kaggle username: aar0npham
Last attempt: 0.4477 on CIFAR100
training spec
num_epochs = 30
batch_size = 128
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-4)
criterion = nn.CrossEntropyLoss(label_smoothing=0.1)
scheduler = optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=5, T_mult=2, eta_min=1e-6)Transformations for train and test respectively:
train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(CIFAR100_MEAN, CIFAR100_STD),
])
test = transforms.Compose([transforms.ToTensor(), transforms.Normalize(CIFAR100_MEAN, CIFAR100_STD)])Model: fine tuned version of EfficientNetV2 trained on ImageNet21k from (Tan & Le, 2021)
reasoning
reference: paper
EfficientNetV2 includes a optimisations to make training a lot faster while keeping the model relatively lean. They were built on top of a limited search space and a fused conv layers called Fused-MBConv.
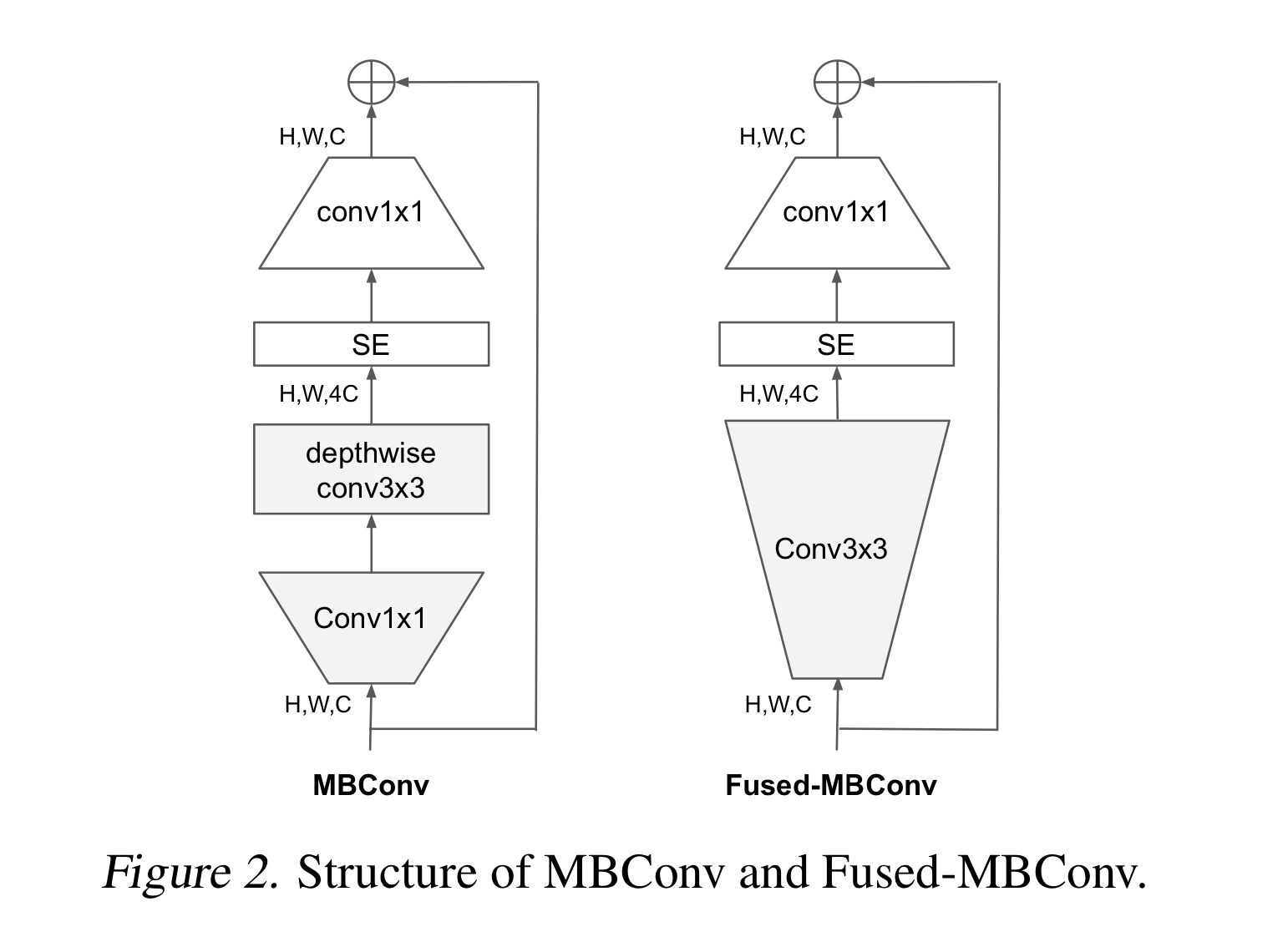
I attempted to replicate the paper’s dropout and adaptive regularization but didn’t see a lot of benefits as mentioned from the paper itself.
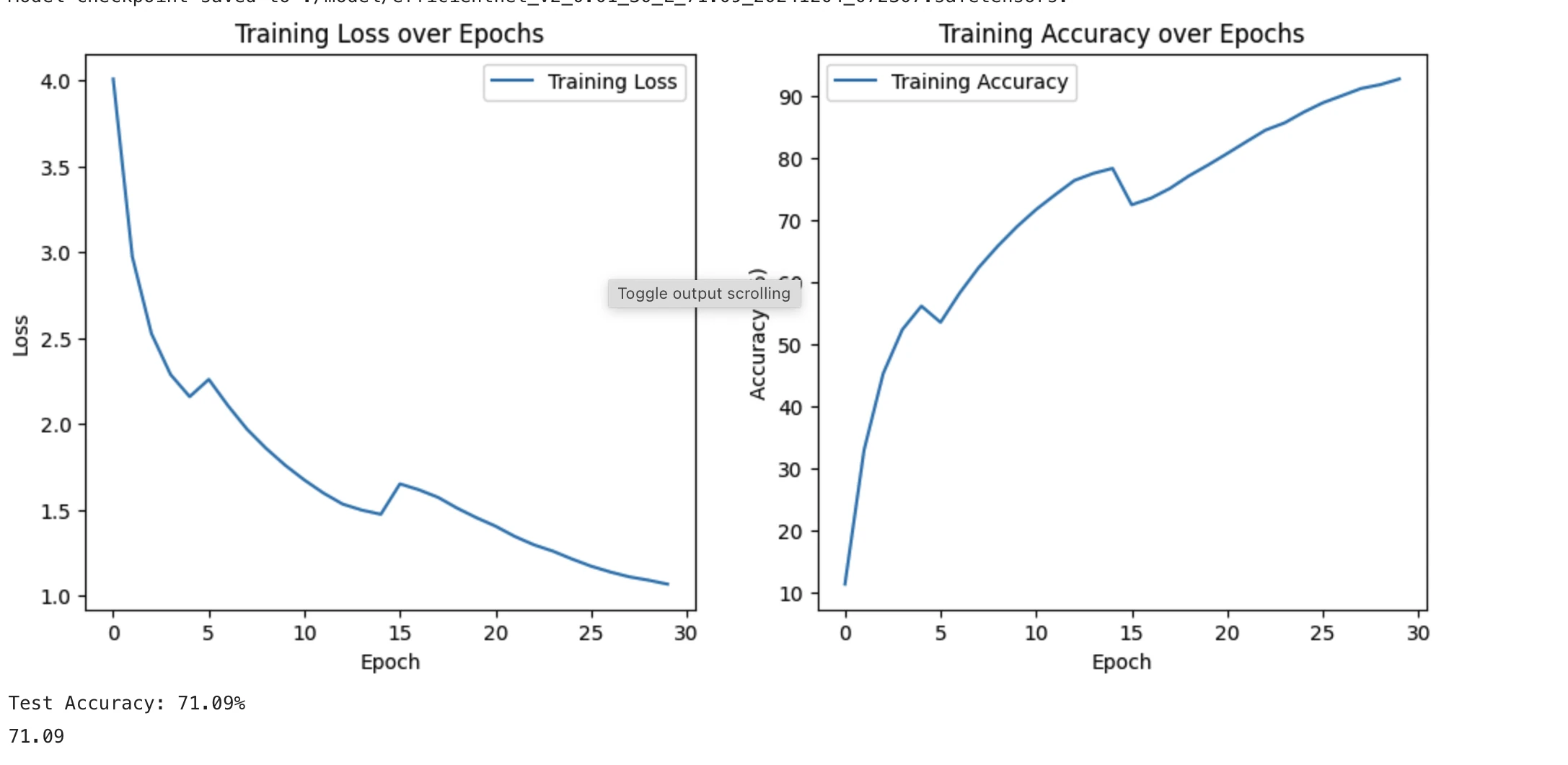
Improvement:
- Could have probably run on a longer epochs training durations
- I tried
AdamWbut results in overfitting way too fast comparing toSGD
code
# uv pip install pandas safetensors torch scipy tqdm torchvision torch torchinfo timm tensorboard
import os, inspect
from datetime import datetime
from typing import Literal
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
from PIL import Image
from torchinfo import summary
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader, Dataset, random_split, Subset
from safetensors.torch import save_model, load_model
# Define CIFAR-100 mean and std
CIFAR100_MEAN = (0.5071, 0.4867, 0.4408)
CIFAR100_STD = (0.2675, 0.2565, 0.2761)
# Hyperparameters
num_epochs = 30
lr = 0.001
weight_decay = 1e-4
batch_size = 128
model_prefix = f'efficientnet_v2_{lr}_{num_epochs}'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
ncols = 100
# CIFAR-100 dataset (download and create DataLoader)
def get_dataloaders(batch_size):
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(CIFAR100_MEAN, CIFAR100_STD),
])
transform_test = transforms.Compose([transforms.ToTensor(), transforms.Normalize(CIFAR100_MEAN, CIFAR100_STD)])
train_dataset = torchvision.datasets.CIFAR100(root='./data', train=True, download=True, transform=transform_train)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
test_dataset = torchvision.datasets.CIFAR100(root='./data', train=False, download=True, transform=transform_test)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
return train_loader, test_loader
def _holistic_patch(model, num_features=100):model.classifier[1]=nn.Linear(model.classifier[1].in_features, num_features)
# Load EfficientNetV2 model
def init_model(variants: Literal['S', 'M', 'L'] = 'S', patch=_holistic_patch):
if variants == 'S' : model = models.efficientnet_v2_s(weights=models.EfficientNet_V2_S_Weights.DEFAULT)
elif variants == 'M': model = models.efficientnet_v2_m(weights=models.EfficientNet_V2_M_Weights.DEFAULT)
elif variants == 'L': model = models.efficientnet_v2_l(weights=models.EfficientNet_V2_L_Weights.DEFAULT)
patch(model)
model.variants = variants
model = model.to(device)
return model
# Load model if exists
def load_checkpoint(filepath, model=None, variants='S'):
if model is None: model = init_model(variants)
load_model(model, filepath)
model.eval()
return model
# Save model to safetensors
def save_checkpoint(model, accuracy, model_prefix, basedir="./model"):
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
os.makedirs(basedir, exist_ok=True)
variants = "default"
if hasattr(model, "variants"): variants = model.variants
filepath = os.path.join(basedir, f'{model_prefix}_{variants}_{accuracy:.2f}_{timestamp}.safetensors')
save_model(model, filepath)
print(f'Model checkpoint saved to {filepath}.')
# Train the model
def train(model, train_loader,
criterion, optimizer, scheduler,
num_epochs,
*, ncols=100):
best_accuracy = 0.0
train_losses = []
train_accuracies = []
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
with tqdm(enumerate(train_loader), total=len(train_loader), ncols=ncols) as bar:
for i, (images, labels) in bar:
images, labels = images.to(device), labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
bar.set_description(f'Epoch [{epoch + 1}/{num_epochs}]')
bar.set_postfix(loss=loss.item())
scheduler.step()
epoch_loss = running_loss / len(train_loader)
epoch_acc = 100 * correct / total
train_losses.append(epoch_loss)
train_accuracies.append(epoch_acc)
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {epoch_loss:.4f}, Accuracy: {epoch_acc:.2f}%')
# Evaluate the model on test set after each epoch
test_acc = evaluate(model, test_loader)
if test_acc > best_accuracy:
best_accuracy = test_acc
save_checkpoint(model, best_accuracy, model_prefix)
# Plotting training history
plot_training_history(train_losses, train_accuracies)
# Evaluate the model
def evaluate(model, test_loader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'Test Accuracy: {accuracy:.2f}%')
return accuracy
# Plot training history
def plot_training_history(train_losses, train_accuracies):
plt.figure(figsize=(12, 5))
# Plot training loss
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.legend()
# Plot training accuracy
plt.subplot(1, 2, 2)
plt.plot(train_accuracies, label='Training Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Training Accuracy over Epochs')
plt.legend()
plt.show()
def validations(model, test_loader, classes, num_examples=16):
model.eval()
SAMPLES, PREDS, LABELS = [], [], []
with torch.no_grad():
for _ in range(num_examples):
idx = np.random.randint(len(test_loader.dataset))
sample_image, actual_label = test_loader.dataset[idx]
sample_image = sample_image.unsqueeze(0).to(device)
SAMPLES.append(sample_image.squeeze(0))
LABELS.append(actual_label)
output = F.softmax(model(sample_image), dim=-1)
pred_values, pred_labels = output.max(-1)
PREDS.append(round(float(pred_values), 4))
LABELS.append(int(pred_labels))
fig, ax = plt.subplots(nrows=4, ncols=4, figsize=(21, 19))
i = 0
for R in range(4):
for C in range(4):
image_np = SAMPLES[i].cpu().numpy().transpose(1, 2, 0)
image_np = (image_np * np.array((0.2675, 0.2565, 0.2761)) + np.array((0.5071, 0.4867, 0.4408))) # Unnormalize
image_np = np.clip(image_np, 0, 1)
ax[R, C].imshow(image_np)
ax[R, C].set_title('Actual: ' + classes[LABELS[i]], fontsize=16).set_color('k')
ax[R, C].set_ylabel(PREDS[i], fontsize=16, rotation=0, labelpad=25).set_color('m')
if LABELS[i] == LABELS[i]:
ax[R, C].set_xlabel('Predicted: ' + classes[LABELS[i]], fontsize=16).set_color('b')
else:
ax[R, C].set_xlabel('Predicted: ' + classes[LABELS[i]], fontsize=16).set_color('r')
ax[R, C].set_xticks([])
ax[R, C].set_yticks([])
i += 1
plt.show()
if __name__ == "__main__":
model = init_model(variants="L")
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9, weight_decay=1e-4)
criterion = nn.CrossEntropyLoss(label_smoothing=0.1) # Add label smoothing
scheduler = optim.lr_scheduler.CosineAnnealingWarmRestarts(
optimizer,
T_0=5, T_mult=2, eta_min=1e-6
)
train(model, train_loader, criterion, optimizer, scheduler, num_epochs, ncols=ncols)
evaluate(model, test_loader)