idea: reduce number of KV heads nk to a fraction nk′=knq of number of query heads nq (evenly dividing the query heads into nk groups with r heads)
value: KV cache tensor (stored in GPU in a paged layout)
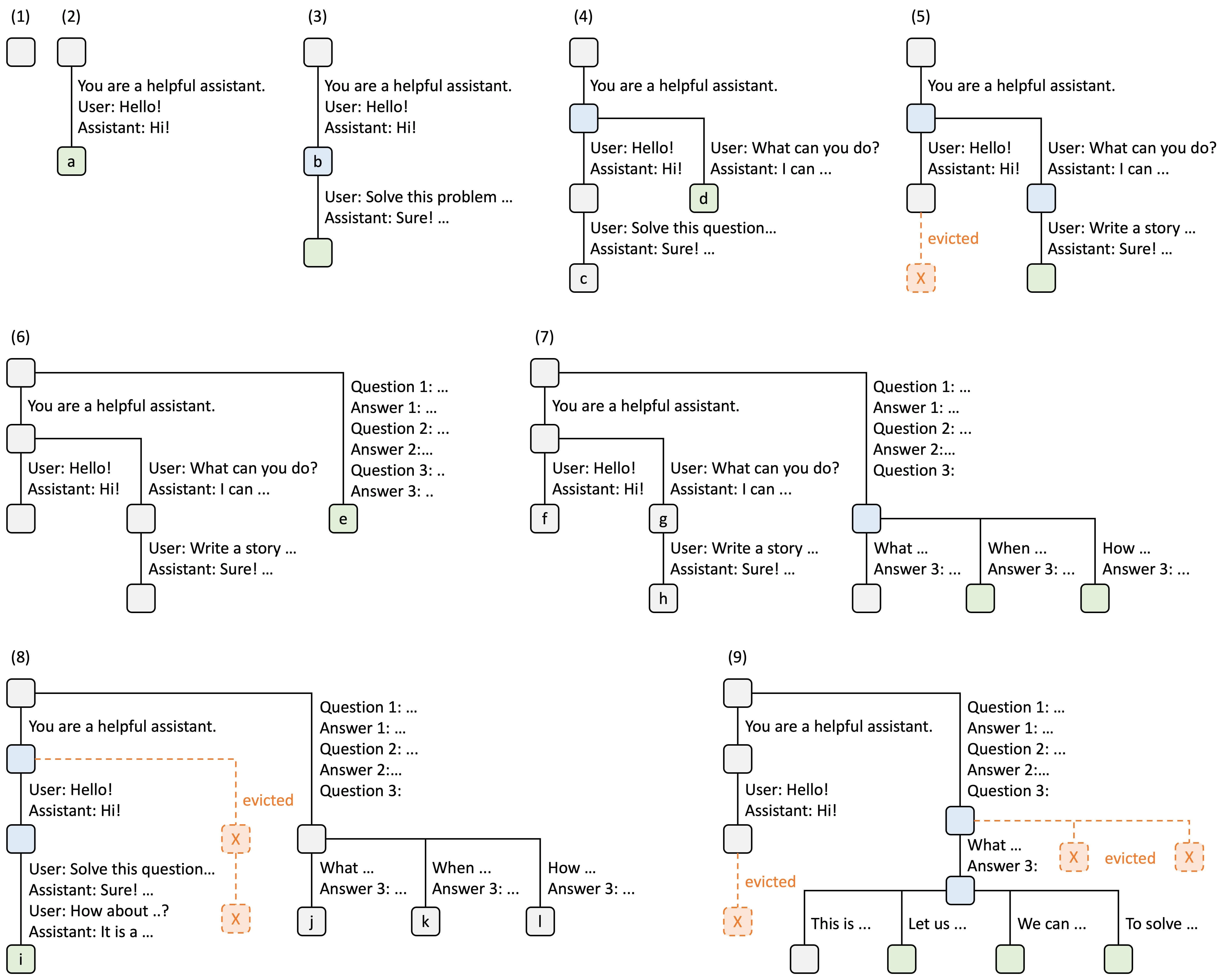
dynamic evolution of the radix tree in response to various requests.
explanation of RadixAttention with LRU eviction policy
These requests include two chat ses,sions, a batch of few-shot learning inquiries, and a self-consistency sampling. Each tree edge carries a label denoting a substring or a sequence of tokens. The nodes are color-coded to reflect different states: green for newly added nodes, blue for cached nodes accessed during the time point, and red for nodes that have been evicted.
if req.size() + current_size ≤ available_size then
new_batch.append(req)
δ←T.increase_ref_counter(req.prefix_node)
available_size ← available_size + δ
end if
end for
Q.remove_requests(new_batch)
// Insert requests into the current running batch
B.merge(new_batch)
// Allocate new memory and do eviction if necessary
needed_size ← B.needed_size()
success, buffer ← P.alloc(needed_size)
if ¬success then
T.evict(needed_size)
success, buffer ← P.alloc(needed_size)
end if
B.run(buffer)
// Process finished requests
finished_requests ← B.drop_finished_requests()
for req ∈ finished_requests do
T.decrease_ref_counter(req.prefix_node)
T.insert(req)
end for
return finished_requests
We got lower bound:
C≥e∈edges(T)∑∣e∣
Consider we visit radix tree T in DFS order. For each edge e of T, the first time we compute KV cache associated with e, then we will compute the whole subtree of e.
During computation of e subtree, then edge e will be continuously hit, thus no additional computation will happen.
cache hit
with cache size ≥ maximum request length (which will equals to longest path in radix tree), edge eWILL NOT be evicted during computation of its subtree
since the common prefix including e of the subtree will be continuously hit.
We can show that longest-shared-prefix-first order is equivalent to DFS order by induction 1
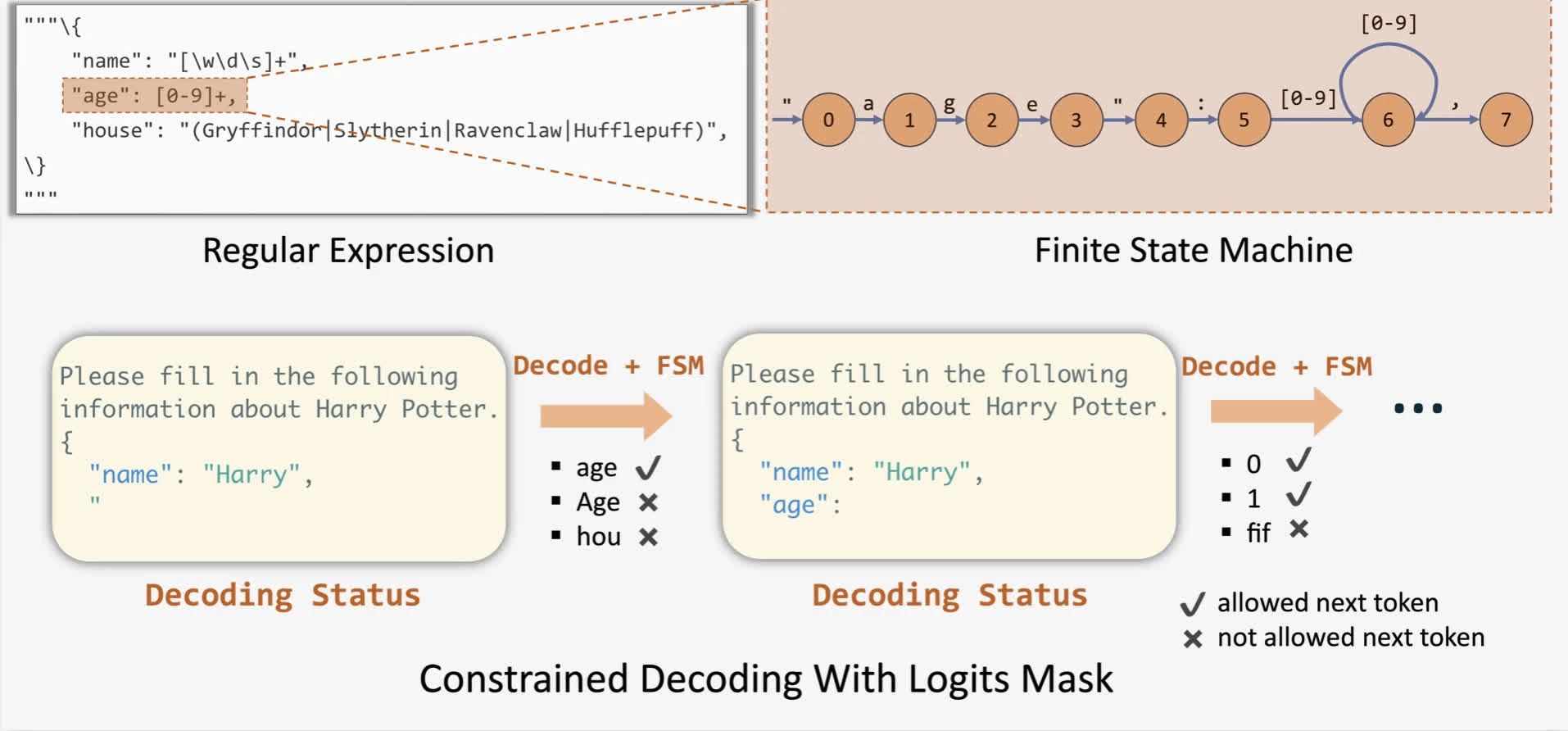
intuition: Using FSM (Willard & Louf, 2023) to guide generations by increasing logit bias for tokens that conform to given JSON schema. This allows us to track the current state during decoding and filter out invalid tokens by applying logit bias to the output.
figure3: Decoding with FSM
limitation: we can see that given construction of FSM requires token-level access, it can only transition the state by only one token at a time, resulting in slow decoding.
Method 2: Interleaved-based
intuition: breaks down JSON schemas, each containing either a chunk prefill part or constrained decoding part. They are then executed interleaved by inference system.
Faster than per-token decoding given that chunked prefill components can process multiple tokens per forward pass
interleaved-based require custom syntax, making it less expressive compared to regex.
struggles to deal with tokenization boundaries due to conflicts between decode and chunked prefill segments.
frequent communications between interpreter and back-end adds additional overhead.
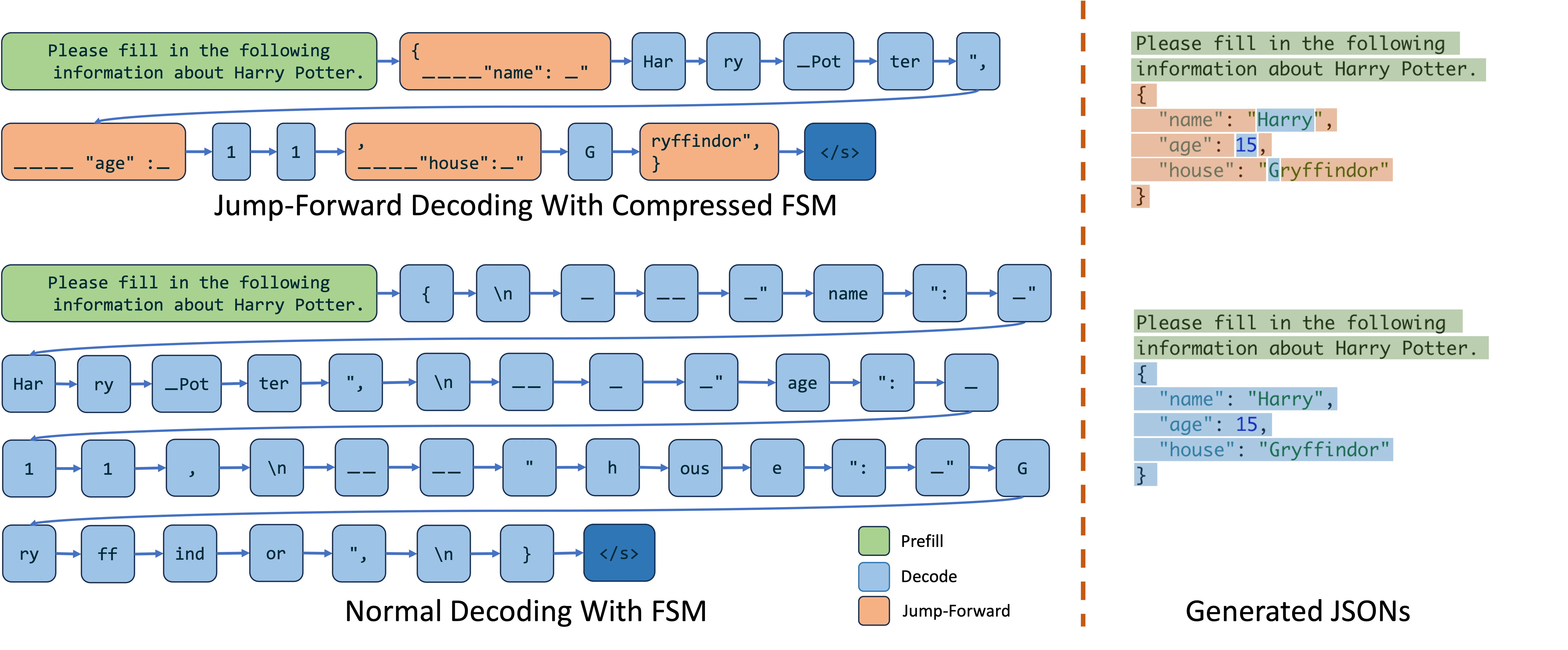
Method 3: Jump-Forward Decoding with compressed FSM
figure4: Jump-forward decoding via compressed FSM
tokenization boundary handling
During decoding, it is preferred to combine multiple characters into a single tokens.
For example, when decoding "Hello" in context of JSON decoding, LLM might output the following token ", He, llo, ",
This may cause some strange behaviour if we combine the last " with , (this regex "[\w\d\s]*" with the last , will lead to endless decoding because this token ", is not valid even if the LM wants to stop.)
Fix:
implement re-tokenization mechanism during jump-forward phase (append string instead of the tokens, followed with re-tokenization of the entire text) → add approximately 4% of overhead
use a comprehensive regex to guide the decoding phase, instead of employing multiple concatenated regex 2
this phenomena is also known as coalescence in structured generations, where it exploit deterministic structures in desired outputs to skip expensive forward pass ↩
Bibliographie
Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y., Lebrón, F., & Sanghai, S. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. arXiv preprint arXiv:2305.13245 [arXiv]
DeepSeek-AI, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, X., Yu, X., Wu, Y., Wu, Z. F., Gou, Z., Shao, Z., Li, Z., Gao, Z., … Zhang, Z. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint arXiv:2501.12948 [arXiv]
Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., DasSarma, N., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., … Olah, C. (2021). A Mathematical Framework for Transformer Circuits. Transformer Circuits Thread. [transformer circuit]
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., & Stoica, I. (2023). Efficient Memory Management for Large Language Model Serving with PagedAttention. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles.
Liu, H., Zaharia, M., & Abbeel, P. (2023). Ring Attention with Blockwise Transformers for Near-Infinite Context. arXiv preprint arXiv:2310.01889 [arXiv]
Shyam, V., Pilault, J., Shepperd, E., Anthony, Q., & Millidge, B. (2025). Tree Attention: Topology-aware Decoding for Long-Context Attention on GPU clusters. arXiv preprint arXiv:2408.04093 [arXiv]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2023). Attention Is All You Need. arXiv preprint arXiv:1706.03762 [arXiv]
Zheng, L., Yin, L., Xie, Z., Sun, C., Huang, J., Yu, C. H., Cao, S., Kozyrakis, C., Stoica, I., Gonzalez, J. E., Barrett, C., & Sheng, Y. (2024). SGLang: Efficient Execution of Structured Language Model Programs. arXiv preprint arXiv:2312.07104 [arXiv]
Zheng, L., Yin, L., Xie, Z., Sun, C., Huang, J., Yu, C. H., Cao, S., Kozyrakis, C., Stoica, I., Gonzalez, J. E., Barrett, C., & Sheng, Y. (2024). SGLang: Efficient Execution of Structured Language Model Programs. arXiv preprint arXiv:2312.07104 [arXiv]
Willard, B. T., & Louf, R. (2023). Efficient Guided Generation for Large Language Models. arXiv preprint arXiv:2307.09702 [arXiv]