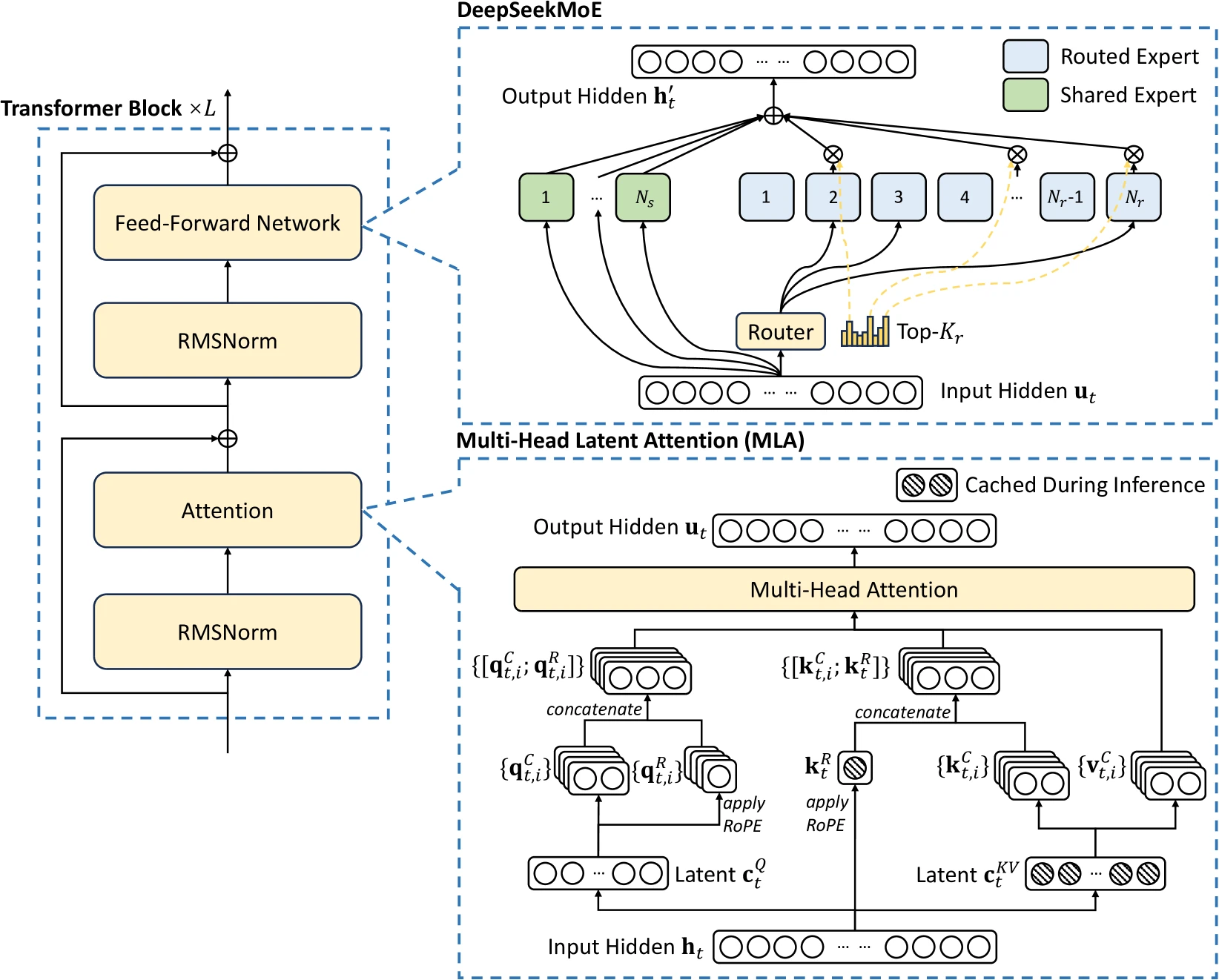
Most of the innovation wrt RL can be found in the DeepSeekMath paper ↩
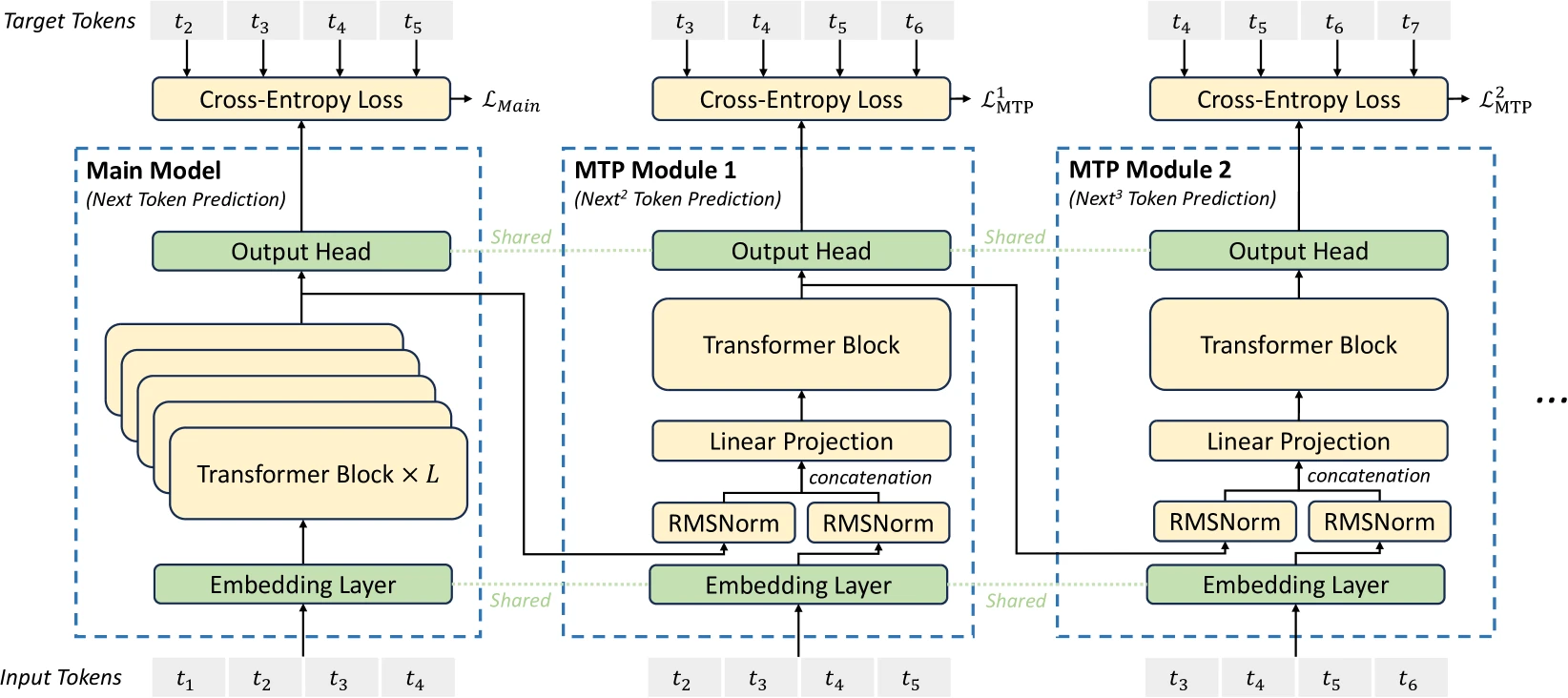
Gloeckle et al. (2024) employs n=4. The order of the forward and backward in a n-token prediction model with n=4 heads of the shared trunk works as follow:
z = model.shared(x)d = z.detach()d.requires_grad = Falsefor i in range(n): p = model.heads[i](d) loss(p, y[i]).backward()z.backward()
DeepSeek-AI, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, X., Yu, X., Wu, Y., Wu, Z. F., Gou, Z., Shao, Z., Li, Z., Gao, Z., … Zhang, Z. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint arXiv:2501.12948 [arXiv]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y. K., Wu, Y., & Guo, D. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv preprint arXiv:2402.03300 [arXiv]
Gloeckle, F., Idrissi, B. Y., Rozière, B., Lopez-Paz, D., & Synnaeve, G. (2024). Better & Faster Large Language Models via Multi-token Prediction. arXiv preprint arXiv:2404.19737 [arXiv]