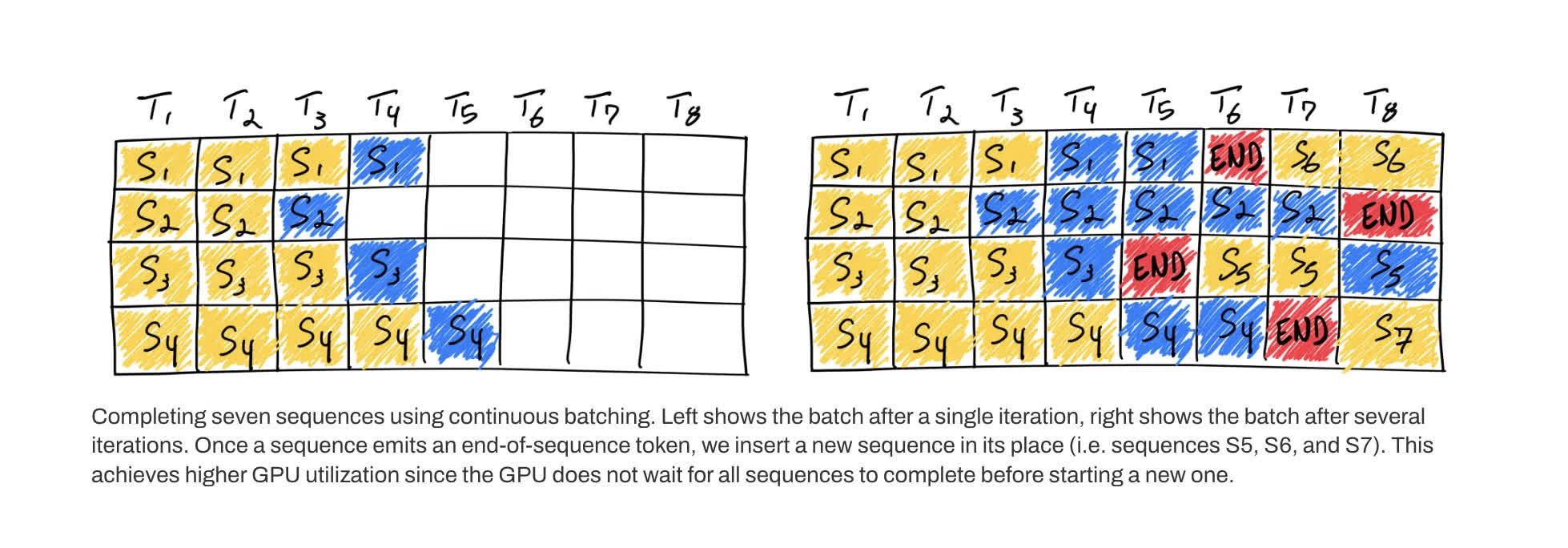
(Yu et al., 2022) solves the static batching to reduce cost and improve throughput by appending requests continuously into existing KV cache 1
Remarque
-
The paper and presentation for the paper. Most notable open source implementation is vLLM.
p/s: Actually, I think first implemented in huggingface/tgi ↩