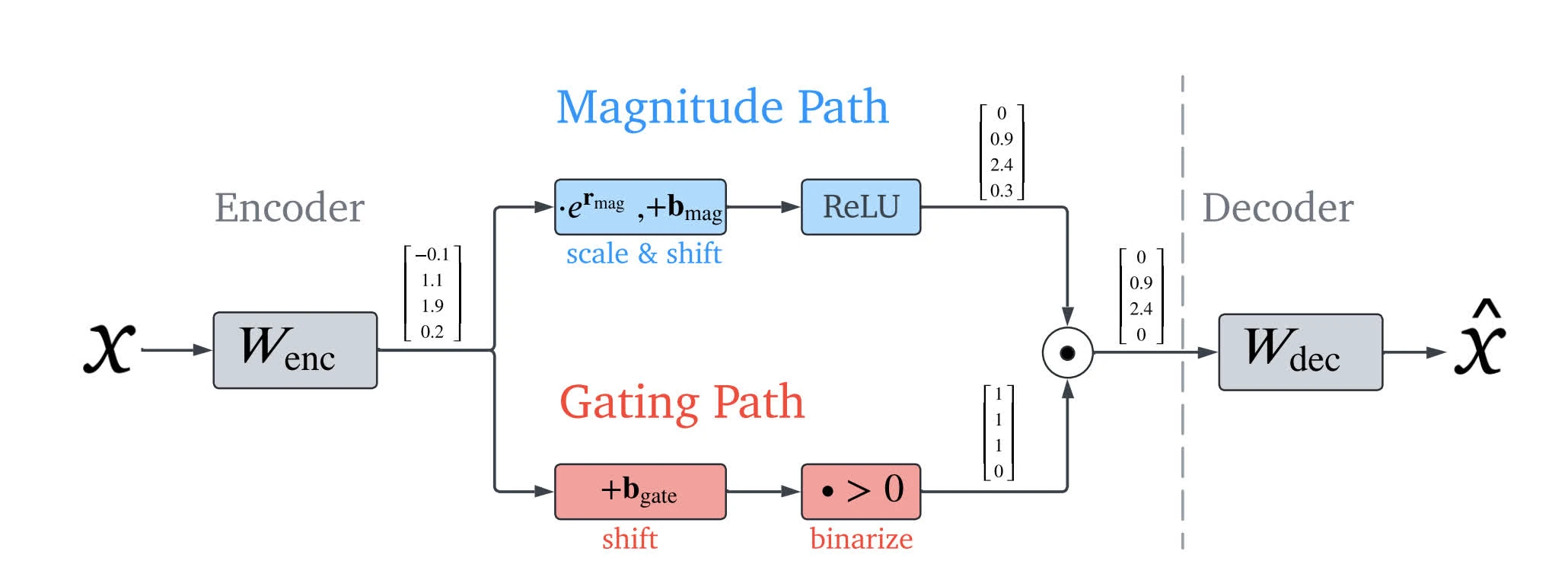
Often contains one layers of MLP with few linear ReLU that is trained on a subset of datasets the main LLMs is trained on.
empirical example: if we wish to interpret all features related to the author Camus, we might want to train an SAEs based on all given text of Camus to interpret “similar” features from Llama-3.1
definition
We wish to decompose a models’ activation x∈Rn into sparse, linear combination of feature directions:
x∼x0+∵i=1∑Mfi(x)didiM≫n: latent unit-norm feature directionfi(x)≥0: corresponding feature activation for x
Thus, the baseline architecture of SAEs is a linear autoencoder with L1 penalty on the activations:
We need to reconstruction fidelity at a given sparsity level, as measured by
L0 via a mixture of reconstruction fidelity and L1 regularization.
We can reduce sparsity loss term without affecting reconstruction by scaling up norm of
decoder weights, or constraining norms of columns Wdec during training
Ideas: output of decoder f(x) has two roles
detects what features acre active ⇐ L1 is crucial to ensure sparsity in decomposition
estimates magnitudes of active features ⇐ L1 is unwanted bias
Loss function of SAEs combines a MSE reconstruction loss with sparsity term:
L(x,f(x),y)=∥y−x∥2/d+c∣f(x)∣∵d: dimensionality of x
the reconstruction is not perfect, given that only one is reconstruction. For smaller value of f(x), features will be suppressed
illustrated example
consider one binary feature in one dimension x=1 with probability p and x=0 otherwise. Ideally, optimal SAE would extract feature activation of f(x)∈{0,1} and have decoder Wd=1
However, if we train SAE optimizing loss function L(x,f(x),y), let say encoder outputs feature activation a if x=1 and 0 otherwise, ignore bias term, the optimization problem becomes:
If we hold x^(∙) fixed, thus L1 pushes f(x)→0, while reconstruction loss pushes f(x) high enough to produce accurate reconstruction.
An optimal value is somewhere between.
However, rescaling the shrink feature activations (Sharkey, 2024) is not necessarily enough to overcome bias induced by L1: a SAE might learnt sub-optimal encoder and decoder directions that is not improved by the fixed. ↩
Bibliographie
Dauphin, Y. N., Fan, A., Auli, M., & Grangier, D. (2017). Language Modeling with Gated Convolutional Networks. arXiv preprint arXiv:1612.08083 [arXiv]
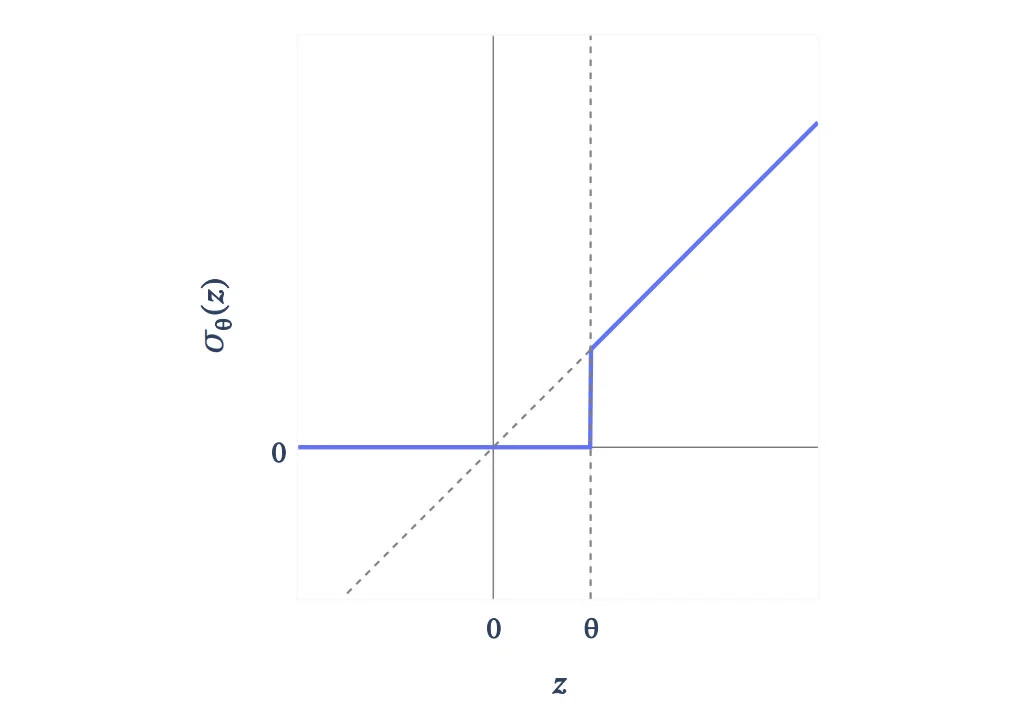
Erichson, N. B., Yao, Z., & Mahoney, M. W. (2019). JumpReLU: A Retrofit Defense Strategy for Adversarial Attacks. arXiv preprint arXiv:1904.03750 [arXiv]
Rajamanoharan, S., Conmy, A., Smith, L., Lieberum, T., Varma, V., Kramár, J., Shah, R., & Nanda, N. (2024). Improving Dictionary Learning with Gated Sparse Autoencoders. arXiv preprint arXiv:2404.16014 [arXiv]
Sharkey, L. (2024). Addressing Feature Suppression in SAEs. AI Alignment Forum. [alignment forum]